Web Lessions from the HTB Academy
HyperText Transfer Protocol (HTTP)
Today, the majority of the applications we use constantly interact with the internet, both web and mobile applications. Most internet communications are made with web requests through the HTTP protocol. HTTP is an application-level protocol used to access the World Wide Web resources. The term hypertext stands for text containing links to other resources and text that the readers can easily interpret.
HTTP communication consists of a client and a server, where the client requests the server for a resource. The server processes the requests and returns the requested resource. The default port for HTTP communication is port 80, though this can be changed to any other port, depending on the web server configuration. The same requests are utilized when we use the internet to visit different websites. We enter a Fully Qualified Domain Name (FQDN) as a Uniform Resource Locator (URL) to reach the desired website, like www.hackthebox.com.
URL
Resources over HTTP are accessed via a URL, which offers many more specifications than simply specifying a website we want to visit. Let’s look at the structure of a URL: 
Here is what each component stands for:
| Component | Example | Description |
|---|---|---|
Scheme | http:// https:// | This is used to identify the protocol being accessed by the client, and ends with a colon and a double slash (://) |
User Info | admin:password@ | This is an optional component that contains the credentials (separated by a colon :) used to authenticate to the host, and is separated from the host with an at sign (@) |
Host | inlanefreight.com | The host signifies the resource location. This can be a hostname or an IP address |
Port | :80 | The Port is separated from the Host by a colon (:). If no port is specified, http schemes default to port 80 and https default to port 443 |
Path | /dashboard.php | This points to the resource being accessed, which can be a file or a folder. If there is no path specified, the server returns the default index (e.g. index.html). |
Query String | ?login=true | The query string starts with a question mark (?), and consists of a parameter (e.g. login) and a value (e.g. true). Multiple parameters can be separated by an ampersand (&). |
Fragments | #status | Fragments are processed by the browsers on the client-side to locate sections within the primary resource (e.g. a header or section on the page). |
Not all components are required to access a resource. The main mandatory fields are the scheme and the host, without which the request would have no resource to request.
HTTP Flow

The diagram above presents the anatomy of an HTTP request at a very high level. The first time a user enters the URL (inlanefreight.com) into the browser, it sends a request to a DNS (Domain Name Resolution) server to resolve the domain and get its IP. The DNS server looks up the IP address for inlanefreight.com and returns it. All domain names need to be resolved this way, as a server can’t communicate without an IP address.
Note: Our browsers usually first look up records in the local ‘/etc/hosts‘ file, and if the requested domain does not exist within it, then they would contact other DNS servers. We can use the ‘/etc/hosts‘ to manually add records to for DNS resolution, by adding the IP followed by the domain name.
Once the browser gets the IP address linked to the requested domain, it sends a GET request to the default HTTP port (e.g. 80), asking for the root / path. Then, the web server receives the request and processes it. By default, servers are configured to return an index file when a request for / is received.
In this case, the contents of index.html are read and returned by the web server as an HTTP response. The response also contains the status code (e.g. 200 OK), which indicates that the request was successfully processed. The web browser then renders the index.html contents and presents it to the user.
Note: This module is mainly focused on HTTP web requests. For more on HTML and web applications, you may refer to the Introduction to Web Applications module.
cURL
In this module, we will be sending web requests through two of the most important tools for any web penetration tester, a Web Browser, like Chrome or Firefox, and the cURL command line tool.
cURL (client URL) is a command-line tool and library that primarily supports HTTP along with many other protocols. This makes it a good candidate for scripts as well as automation, making it essential for sending various types of web requests from the command line, which is necessary for many types of web penetration tests.
We can send a basic HTTP request to any URL by using it as an argument for cURL, as follows:
HyperText Transfer Protocol (HTTP)
Michael Mancuso@htb[/htb]$ curl inlanefreight.com
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
...SNIP...
We see that cURL does not render the HTML/JavaScript/CSS code, unlike a web browser, but prints it in its raw format. However, as penetration testers, we are mainly interested in the request and response context, which usually becomes much faster and more convenient than a web browser.
We may also use cURL to download a page or a file and output the content into a file using the -O flag. If we want to specify the output file name, we can use the -o flag and specify the name. Otherwise, we can use -O and cURL will use the remote file name, as follows:
HyperText Transfer Protocol (HTTP)
Michael Mancuso@htb[/htb]$ curl -O inlanefreight.com/index.html
Michael Mancuso@htb[/htb]$ ls
index.html
As we can see, the output was not printed this time but rather saved into index.html. We noticed that cURL still printed some status while processing the request. We can silent the status with the -s flag, as follows:
HyperText Transfer Protocol (HTTP)
Michael Mancuso@htb[/htb]$ curl -s -O inlanefreight.com/index.html
This time, cURL did not print anything, as the output was saved into the index.html file. Finally, we may use the -h flag to see what other options we may use with cURL:
HyperText Transfer Protocol (HTTP)
Michael Mancuso@htb[/htb]$ curl -h
Usage: curl [options...] <url>
-d, --data <data> HTTP POST data
-h, --help <category> Get help for commands
-i, --include Include protocol response headers in the output
-o, --output <file> Write to file instead of stdout
-O, --remote-name Write output to a file named as the remote file
-s, --silent Silent mode
-u, --user <user:password> Server user and password
-A, --user-agent <name> Send User-Agent <name> to server
-v, --verbose Make the operation more talkative
This is not the full help, this menu is stripped into categories.
Use "--help category" to get an overview of all categories.
Use the user manual `man curl` or the "--help all" flag for all options.
As the above message mentions, we may use --help all to print a more detailed help menu, or --help category (e.g. -h http) to print the detailed help of a specific flag. If we ever need to read more detailed documentation, we can use man curl to view the full cURL manual page.
The first and most dominant component of the front end of web applications is HTML (HyperText Markup Language). HTML is at the very core of any web page we see on the internet. It contains each page’s basic elements, including titles, forms, images, and many other elements. The web browser, in turn, interprets these elements and displays them to the end-user.
The following is a very basic example of an HTML page:
Example
Code: html
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>A Heading</h1>
<p>A Paragraph</p>
</body>
</html>
This would display the following: 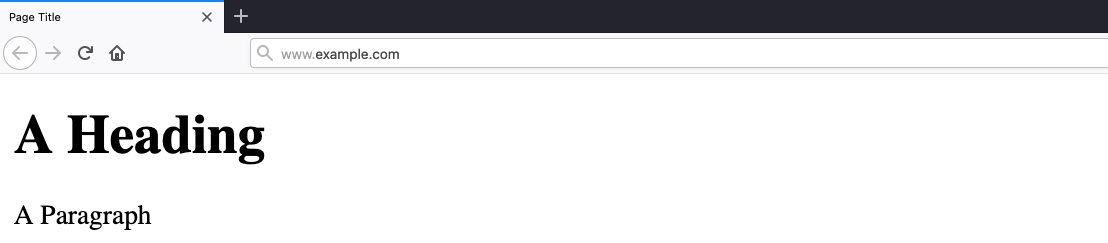
As we can see, HTML elements are displayed in a tree form, similar to XML and other languages:
HTML Structure
HTML
document
- html
-- head
--- title
-- body
--- h1
--- p
Each element can contain other HTML elements, while the main HTML tag should contain all other elements within the page, which falls under document, distinguishing between HTML and documents written for other languages, such as XML documents.
The HTML elements of the above code can be viewed as follows:
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>A Heading</h1>
<p>A Paragraph</p>
</body>
</html>
Each HTML element is opened and closed with a tag that specifies the element’s type ‘e.g. <p> for paragraphs’, where the content would be placed between these tags. Tags may also hold the element’s id or class ‘e.g. <p id='para1'> or <p id='red-paragraphs'>‘, which is needed for CSS to properly format the element. Both tags and the content comprise the entire element.
URL Encoding
An important concept to learn in HTML is URL Encoding, or percent-encoding. For a browser to properly display a page’s contents, it has to know the charset in use. In URLs, for example, browsers can only use ASCII encoding, which only allows alphanumerical characters and certain special characters. Therefore, all other characters outside of the ASCII character-set have to be encoded within a URL. URL encoding replaces unsafe ASCII characters with a % symbol followed by two hexadecimal digits.
For example, the single-quote character ‘'‘ is encoded to ‘%27‘, which can be understood by browsers as a single-quote. URLs cannot have spaces in them and will replace a space with either a + (plus sign) or %20. Some common character encodings are:
| Character | Encoding |
|---|---|
| space | %20 |
| ! | %21 |
| “ | %22 |
| # | %23 |
| $ | %24 |
| % | %25 |
| & | %26 |
| ‘ | %27 |
| ( | %28 |
| ) | %29 |
A full character encoding table can be seen here.
Many online tools can be used to perform URL encoding/decoding. Furthermore, the popular web proxy Burp Suite has a decoder/encoder which can be used to convert between various types of encodings. Try encoding/decoding some characters and strings using this online tool.
Usage
The <head> element usually contains elements that are not directly printed on the page, like the page title, while all main page elements are located under <body>. Other important elements include the <style>, which holds the page’s CSS code, and the <script>, which holds the JS code of the page, as we will see in the next section.
Each of these elements is called a DOM (Document Object Model). The World Wide Web Consortium (W3C) defines DOM as:
"The W3C Document Object Model (DOM) is a platform and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure, and style of a document."
The DOM standard is separated into 3 parts:
Core DOM– the standard model for all document typesXML DOM– the standard model for XML documentsHTML DOM– the standard model for HTML documents
For example, from the above tree view, we can refer to DOMs as document.head or document.h1, and so on.
Understanding the HTML DOM structure can help us understand where each element we view on the page is located, which enables us to view the source code of a specific element on the page and look for potential issues. We can locate HTML elements by their id, their tag name, or by their class name.
This is also useful when we want to utilize front-end vulnerabilities (like XSS) to manipulate existing elements or create new elements to serve our needs.